반응형

🌟 서론
머신러닝(Machine Learning)은 인공지능(AI)의 한 분야로, 컴퓨터가 데이터를 분석하고 학습하여 명시적인 프로그래밍 없이도 스스로 예측하거나 결정을 내릴 수 있는 기술입니다.
오늘날 머신러닝은 스마트폰 음성인식, 추천 시스템, 자율주행 자동차, 금융 사기 탐지 등 다양한 분야에서 사용되고 있습니다.
이번 글에서는 머신러닝의 기본 개념, 작동 방식, 주요 알고리즘, 그리고 활용 사례를 중심으로 머신러닝에 대해 알아보겠습니다. 🚀
📚 본론
1️⃣ 머신러닝이란?

머신러닝은 데이터를 기반으로 컴퓨터가 학습하고, 주어진 데이터에서 패턴을 찾아 예측하거나 의사 결정을 내리는 기술입니다.
기존의 규칙 기반 시스템과 달리, 명시적인 코딩 없이도 컴퓨터가 스스로 개선할 수 있습니다.
머신러닝의 주요 개념
- 학습(Training): 데이터로부터 패턴을 학습하는 과정.
- 모델(Model): 학습된 결과를 바탕으로 새로운 데이터를 예측하거나 분류하는 역할.
- 피처(Feature): 모델이 학습하는 데 사용하는 입력 데이터의 속성.
- 라벨(Label): 모델이 예측해야 할 정답 또는 결과.
머신러닝 vs 전통적인 프로그래밍
| 항목 | 전통적인 프로그래밍 | 머신러닝 |
|---|---|---|
| 작동 방식 | 규칙(Logic)을 사람이 직접 코딩 | 데이터 기반으로 컴퓨터가 규칙 학습 |
| 사용 사례 | 계산기, 데이터베이스 관리 | 추천 시스템, 음성인식, 이미지 분류 |
| 유연성 | 규칙 변경 시 코드 수정 필요 | 데이터 변경 시 자동으로 학습 업데이트 |
2️⃣ 머신러닝의 종류

머신러닝은 학습 방식에 따라 크게 세 가지로 분류됩니다.
🔑 1. 지도 학습(Supervised Learning)
- 정답(라벨)이 있는 데이터를 기반으로 학습하는 방식.
- 입력 데이터와 출력 데이터 간의 관계를 학습.
- 주요 알고리즘: 선형 회귀, 로지스틱 회귀, SVM, 랜덤 포레스트, 신경망.
- 활용 사례:
- 이메일 스팸 필터링 (스팸/정상 분류)
- 주택 가격 예측 (연속 값 예측)
🔑 2. 비지도 학습(Unsupervised Learning)
- 라벨이 없는 데이터를 기반으로 데이터 간의 패턴을 학습.
- 데이터의 군집화 또는 분포 파악.
- 주요 알고리즘: K-평균 클러스터링, PCA(주성분 분석), DBSCAN.
- 활용 사례:
- 고객 세그먼테이션 (고객 그룹 나누기)
- 데이터 시각화
🔑 3. 강화 학습(Reinforcement Learning)
- 에이전트가 환경과 상호작용하며 보상(Reward)을 극대화하는 방향으로 학습.
- 시뮬레이션 환경에서 점진적으로 최적의 행동 학습.
- 주요 알고리즘: Q-러닝, 딥 Q 네트워크(DQN).
- 활용 사례:
- 자율주행 자동차
- 게임 AI (예: 알파고)
3️⃣ 머신러닝의 작동 원리

머신러닝 모델이 학습하는 과정은 다음 단계를 따릅니다.
✅ 1. 데이터 수집
- 데이터를 수집하여 모델 학습의 기반을 만듭니다.
- 예: 사용자 구매 데이터, 이미지 데이터, 로그 파일.
✅ 2. 데이터 전처리
- 데이터를 정리하고 변환하여 학습에 적합한 형태로 만듭니다.
- 결측치 처리, 중복 데이터 제거, 피처 스케일링 등이 포함됩니다.
✅ 3. 모델 선택
- 문제 유형에 따라 적합한 알고리즘(선형 회귀, SVM 등)을 선택합니다.
✅ 4. 학습(Training)
- 데이터를 모델에 입력하여 패턴을 학습합니다.
✅ 5. 평가(Evaluation)
- 테스트 데이터를 사용하여 학습된 모델의 성능을 평가합니다.
- 주요 평가 지표: 정확도, 정밀도, 재현율, F1 점수.
✅ 6. 예측(Prediction)
- 새로운 데이터에 대해 학습된 모델을 사용하여 예측 결과를 생성합니다.
4️⃣ 주요 머신러닝 알고리즘

📌 1. 선형 회귀(Linear Regression)
- 두 변수 간의 선형 관계를 기반으로 예측.
- 활용 사례: 주택 가격, 매출 예측.
📌 2. 로지스틱 회귀(Logistic Regression)
- 데이터를 이진 분류(예: True/False)하는 데 사용.
- 활용 사례: 암 진단(정상/비정상).
📌 3. K-최근접 이웃(K-Nearest Neighbors, KNN)
- 가장 가까운 K개의 데이터를 기반으로 예측.
- 활용 사례: 이미지 분류.
📌 4. 랜덤 포레스트(Random Forest)
- 여러 개의 의사결정 트리를 결합하여 높은 정확도의 예측.
- 활용 사례: 신용 카드 사기 탐지.
📌 5. 서포트 벡터 머신(SVM)
- 데이터를 분류하는 최적의 초평면을 찾는 알고리즘.
- 활용 사례: 텍스트 분류, 이미지 분류.
📌 6. 딥러닝(Deep Learning)
5️⃣ 머신러닝의 활용 사례

✅ 1. 추천 시스템
- 활용 분야: 넷플릭스(영화 추천), 유튜브(동영상 추천), 아마존(제품 추천).
- 머신러닝을 활용해 사용자 선호도를 분석하고 개인화된 추천을 제공합니다.
✅ 2. 자연어 처리(Natural Language Processing, NLP)
- 활용 분야: 채팅봇, 문서 분류, 번역 서비스.
- 언어 데이터(텍스트/음성)를 분석하여 의미를 이해하고 처리합니다.
✅ 3. 이미지 인식
- 활용 분야: 안면 인식, 의료 영상 분석.
- 사진, 비디오 등 시각 데이터를 분석해 패턴을 인식합니다.
✅ 4. 자율주행
- 활용 분야: 테슬라, 웨이모 같은 자율주행 자동차.
- 카메라 및 센서 데이터를 분석해 주변 환경을 이해하고 의사 결정을 내립니다.
✅ 5. 금융
- 활용 분야: 신용 점수 평가, 사기 탐지.
- 금융 데이터를 분석해 위험을 예측하거나 이상 행동을 탐지합니다.
6️⃣ 머신러닝의 도전 과제
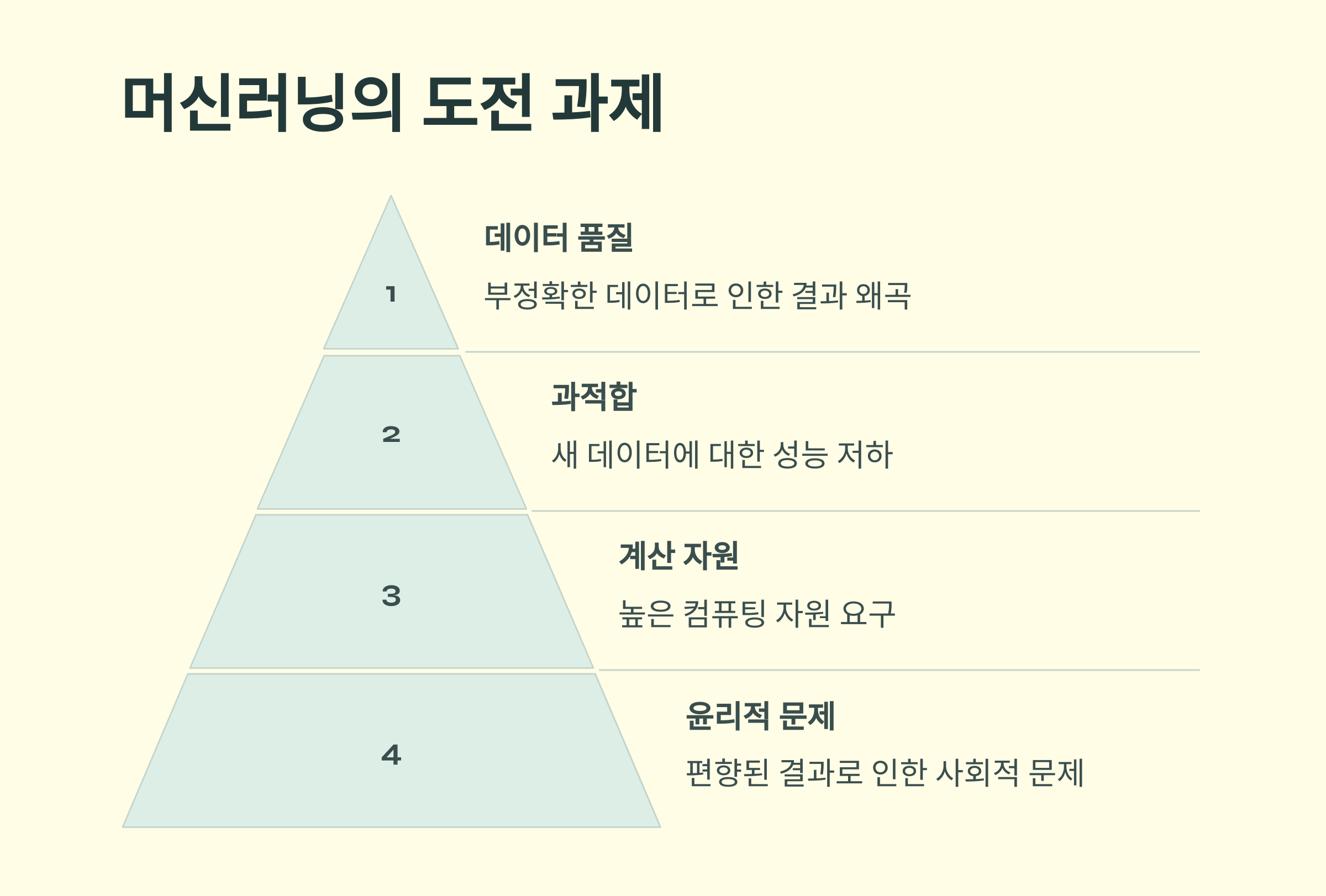
🚫 1. 데이터 품질 문제
- 머신러닝 모델의 성능은 데이터 품질에 크게 의존합니다.
- 잘못된 또는 편향된 데이터는 부정확한 결과를 초래할 수 있습니다.
🚫 2. 과적합(Overfitting)
- 모델이 학습 데이터에 너무 특화되어 새로운 데이터에 대한 성능이 저하되는 문제.
🚫 3. 계산 자원
- 딥러닝과 같은 복잡한 모델은 높은 컴퓨팅 자원(GPU, TPU)을 필요로 합니다.
🚫 4. 윤리적 문제
- 머신러닝 결과가 편향되거나 잘못 사용될 경우 사회적 문제가 발생할 수 있습니다.
🏁 결론
머신러닝은 데이터 중심의 세상에서 우리의 삶을 혁신적으로 변화시키고 있습니다.
추천 시스템, 자율주행, 의료 진단 등 다양한 분야에서 머신러닝은 미래를 이끄는 핵심 기술로 자리 잡고 있습니다.
머신러닝을 배우고 적용하기 위해서는 데이터 분석과 프로그래밍(Python, R 등)에 대한 기본 지식을 갖추고, 다양한 알고리즘과 활용 사례를 실습해 보는 것이 중요합니다.
AI 시대에 발맞춰 머신러닝 기술을 익혀 새로운 기회를 창출해 보세요 🚀
❓ Q&A 섹션

Q1. 머신러닝과 딥러닝의 차이점은 무엇인가요?
- 머신러닝: 데이터에서 패턴을 학습하는 기술로, 딥러닝은 머신러닝의 하위 집합입니다.
- 딥러닝: 인공신경망을 활용하여 대규모 데이터를 학습하며, 복잡한 문제를 해결할 수 있습니다.
Q2. 머신러닝을 배우려면 어떤 언어를 사용해야 하나요?
- 주로 Python을 사용하며, scikit-learn, TensorFlow, PyTorch 같은 라이브러리가 널리 사용됩니다.
Q3. 머신러닝에 얼마나 많은 데이터가 필요한가요?
- 문제의 복잡도와 모델 유형에 따라 다르지만, 일반적으로 데이터가 많을수록 성능이 좋아집니다.
Q4. 머신러닝을 어디서 시작해야 하나요?
- Coursera, Kaggle, Google Colab 등을 활용해 기초 알고리즘과 데이터 분석 과정을 실습하며 시작할 수 있습니다.
반응형